
11 quy tắc quan trọng trong thiết kế Cơ sở dữ liệu
Khi bạn bắt đầu thiết kế cơ sở dữ liệu của mình, điều đầu tiên cần phân tích là bản chất của ứng dụng bạn đang thiết kế, là Giao dịch hay Phân tích. Bạn sẽ thấy nhiều nhà phát triển theo mặc định áp dụng các quy tắc chuẩn hóa mà không nghĩ về bản chất của ứng dụng và sau đó gặp phải các vấn đề về hiệu suất và tùy chỉnh. Như đã nói, có hai loại ứng dụng: dựa trên giao dịch và dựa trên phân tích, chúng ta hãy hiểu những loại này là gì.
>>> Đọc thêm:
KHÓA HỌC DATA WAREHOUSE : TỔNG HỢP, CHUẨN HÓA VÀ XÂY DỰNG KHO DỮ LIỆU TRONG DOANH NGHIỆP
KHÓA HỌC DATA MODEL - THIẾT KẾ MÔ HÌNH DỮ LIỆU TRONG DOANH NGHIỆP
LỘ TRÌNH TRỞ THÀNH DATA ENGINEER CHO NGƯỜI MỚI BẮT ĐẦU
DATA ENGINEER LÀ GÌ? CÔNG VIỆC CHÍNH CỦA DE? CÁC KỸ NĂNG CẦN THIẾT
Giao dịch : Trong loại ứng dụng này, người dùng cuối của bạn quan tâm nhiều hơn đến CRUD, tức là tạo, đọc, cập nhật và xóa bản ghi. Tên chính thức của một loại cơ sở dữ liệu như vậy là OLTP.
Phân tích : Trong các loại ứng dụng này, người dùng cuối của bạn quan tâm nhiều hơn đến việc phân tích, báo cáo, dự báo, v.v. Các loại cơ sở dữ liệu này có số lần chèn và cập nhật ít hơn. Mục đích chính ở đây là tìm nạp và phân tích dữ liệu càng nhanh càng tốt. Tên chính thức của một loại cơ sở dữ liệu như vậy là OLAP.
Nói cách khác, nếu bạn nghĩ rằng chèn, cập nhật và xóa nổi bật hơn thì hãy thiết kế bảng chuẩn hóa, nếu không hãy tạo cấu trúc cơ sở dữ liệu không chuẩn hóa phẳng.
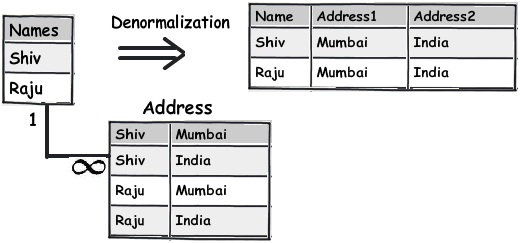
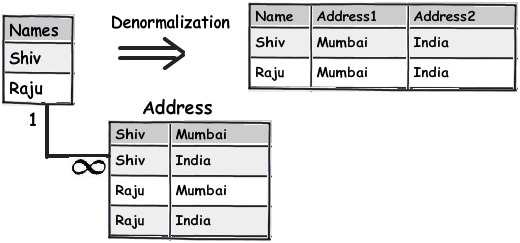
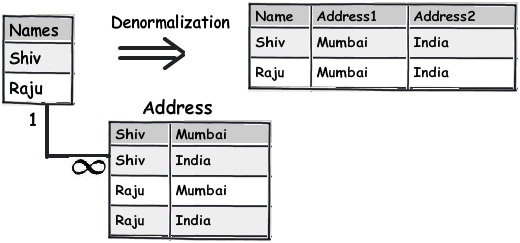
Dưới đây là một sơ đồ đơn giản cho thấy tên và địa chỉ ở phía bên trái là một bảng chuẩn hóa đơn giản như thế nào và bằng cách áp dụng cấu trúc không chuẩn hóa, chúng ta đã tạo ra một cấu trúc bảng phẳng như thế nào.
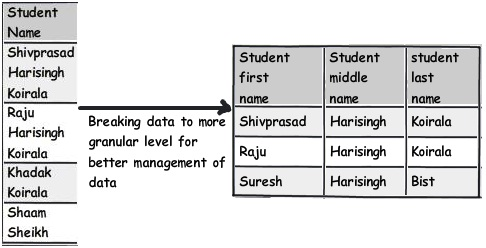
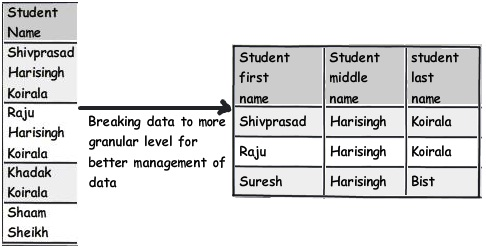
Quy tắc này thực sự là quy tắc đầu tiên từ dạng chuẩn thứ nhất. Một trong những dấu hiệu vi phạm quy tắc này là nếu các truy vấn của bạn đang sử dụng quá nhiều hàm phân tích chuỗi như chuỗi con, charindex, v.v., thì có lẽ quy tắc này cần được áp dụng.
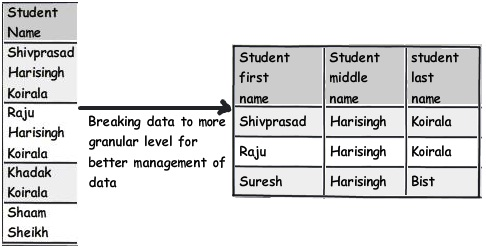
Ví dụ, bạn có thể thấy bảng dưới đây có tên học sinh; nếu bạn muốn truy vấn tên sinh viên có “Koirala” chứ không phải “Haftingh”, bạn có thể tưởng tượng loại truy vấn bạn sẽ kết thúc.
Vì vậy, cách tiếp cận tốt hơn sẽ là chia trường này thành các phần logic hơn nữa để chúng ta có thể viết các truy vấn rõ ràng và tối ưu.
Các nhà phát triển là những sinh vật dễ thương. Nếu bạn nói với họ đây là cách, họ tiếp tục làm; tốt, họ lạm dụng nó dẫn đến những hậu quả không mong muốn. Điều này cũng áp dụng cho quy tắc 2 mà chúng ta vừa nói ở trên. Khi bạn nghĩ về việc phân hủy, hãy tạm dừng và tự hỏi mình, liệu nó có cần thiết không? Như đã nói, sự phân rã phải hợp lý.
Ví dụ, bạn có thể thấy trường số điện thoại; hiếm khi bạn thao tác trên mã ISD của các số điện thoại riêng (cho đến khi ứng dụng của bạn yêu cầu). Vì vậy, sẽ là một quyết định khôn ngoan nếu chỉ để lại nó vì nó có thể dẫn đến nhiều biến chứng hơn.
Tập trung và cấu trúc lại dữ liệu trùng lặp. Lo lắng cá nhân của tôi về dữ liệu trùng lặp không phải là nó chiếm dung lượng đĩa cứng, mà là sự nhầm lẫn mà nó tạo ra.
Ví dụ, trong sơ đồ dưới đây, bạn có thể thấy “Tiêu chuẩn thứ 5” và “Tiêu chuẩn thứ năm” có nghĩa giống nhau. Bây giờ bạn có thể nói rằng dữ liệu đã đi vào hệ thống của bạn do nhập dữ liệu không tốt hoặc xác thực kém. Nếu bạn muốn lấy một báo cáo, họ sẽ hiển thị chúng dưới dạng các thực thể khác nhau, điều này rất khó hiểu theo quan điểm của người dùng cuối.
Một trong những giải pháp sẽ là chuyển toàn bộ dữ liệu sang một bảng tổng thể khác và tham chiếu chúng qua các khóa ngoại. Bạn có thể thấy trong hình bên dưới cách chúng tôi đã tạo một bảng chính mới có tên là “Tiêu chuẩn” và liên kết giống nhau bằng cách sử dụng một khóa ngoại đơn giản.
Nguyên tắc thứ hai trong tổng số 1 st hình thức bình thường nói nhóm tránh lặp lại. Một trong những ví dụ về nhóm lặp lại được giải thích trong sơ đồ dưới đây. Nếu bạn nhìn kỹ trường giáo trình, chúng ta có quá nhiều dữ liệu trong một trường. Các loại trường này được gọi là “Nhóm lặp lại”. Nếu chúng ta phải thao tác dữ liệu này, truy vấn sẽ phức tạp và tôi cũng nghi ngờ về hiệu suất của các truy vấn.
Những loại cột có dữ liệu được nhồi với dấu phân cách cần được chú ý đặc biệt và cách tiếp cận tốt hơn sẽ là chuyển các trường đó sang một bảng khác và liên kết chúng với các khóa để quản lý tốt hơn.
Vì vậy, bây giờ chúng ta hãy áp dụng quy tắc thứ hai của dạng chuẩn thứ nhất: “Tránh lặp lại các nhóm”. Bạn có thể thấy trong hình trên, tôi đã tạo một bảng giáo trình riêng và sau đó tạo mối quan hệ nhiều-nhiều với bảng chủ đề.
Với cách tiếp cận này, trường giáo trình trong bảng chính không lặp lại nữa và có các dấu tách dữ liệu.
 Để ý các trường phụ thuộc một phần vào khóa chính. Ví dụ trong bảng trên, chúng ta có thể thấy khóa chính được tạo trên số cuộn và tiêu chuẩn. Bây giờ hãy quan sát lĩnh vực giáo trình một cách chặt chẽ. Trường giáo trình được liên kết với một tiêu chuẩn chứ không phải với học sinh trực tiếp (số cuộn).
Để ý các trường phụ thuộc một phần vào khóa chính. Ví dụ trong bảng trên, chúng ta có thể thấy khóa chính được tạo trên số cuộn và tiêu chuẩn. Bây giờ hãy quan sát lĩnh vực giáo trình một cách chặt chẽ. Trường giáo trình được liên kết với một tiêu chuẩn chứ không phải với học sinh trực tiếp (số cuộn).
Giáo trình gắn liền với tiêu chuẩn mà sinh viên đang học chứ không phải trực tiếp với sinh viên. Vì vậy, nếu ngày mai chúng ta muốn cập nhật giáo trình chúng ta phải cập nhật cho từng học sinh, điều này rất khó và không logic. Sẽ có ý nghĩa hơn khi di chuyển các trường này ra ngoài và liên kết chúng với bảng Chuẩn.
Bạn có thể thấy cách chúng tôi đã di chuyển trường giáo trình và gắn nó vào bảng Tiêu chuẩn.
Quy tắc này không là gì ngoài dạng bình thường thứ 2 : “Tất cả các khóa phải phụ thuộc vào khóa chính đầy đủ chứ không phải một phần”.
Nếu bạn đang làm việc trên các ứng dụng OLTP, việc loại bỏ các cột dẫn xuất sẽ là một suy nghĩ tốt, trừ khi có một số lý do cấp bách về hiệu suất. Trong trường hợp OLAP, nơi chúng tôi thực hiện rất nhiều phép tính, tổng kết, các loại trường này là cần thiết để đạt được hiệu suất.
Trong hình trên, bạn có thể thấy trường trung bình phụ thuộc vào điểm và chủ đề như thế nào. Đây cũng là một trong những hình thức dự phòng. Vì vậy, đối với những loại trường bắt nguồn từ các trường khác, hãy suy nghĩ: chúng có thực sự cần thiết không?
Quy tắc này cũng được gọi là dạng chuẩn thứ 3 : “Không có cột nào nên phụ thuộc vào các cột không phải khóa chính khác”. Cá nhân tôi nghĩ rằng đừng áp dụng quy tắc này một cách mù quáng, hãy xem tình hình; nó không phải là dữ liệu dư thừa luôn luôn xấu. Nếu dữ liệu dư thừa là dữ liệu tính toán, hãy xem tình huống và sau đó quyết định xem bạn có muốn triển khai dạng chuẩn thứ 3 hay không .
 Đừng biến nó thành một quy tắc nghiêm ngặt mà bạn sẽ luôn tránh được sự dư thừa. Nếu có nhu cầu cấp bách về hiệu suất, hãy nghĩ đến việc khử chuẩn hóa. Trong quá trình chuẩn hóa, bạn cần tạo các phép nối với nhiều bảng và trong quá trình không chuẩn hóa, các phép nối sẽ giảm và do đó tăng hiệu suất.
Đừng biến nó thành một quy tắc nghiêm ngặt mà bạn sẽ luôn tránh được sự dư thừa. Nếu có nhu cầu cấp bách về hiệu suất, hãy nghĩ đến việc khử chuẩn hóa. Trong quá trình chuẩn hóa, bạn cần tạo các phép nối với nhiều bảng và trong quá trình không chuẩn hóa, các phép nối sẽ giảm và do đó tăng hiệu suất.
Các dự án OLAP chủ yếu xử lý dữ liệu đa chiều. Ví dụ, bạn có thể thấy hình dưới đây, bạn muốn nhận doanh số theo quốc gia, khách hàng và ngày. Nói cách đơn giản, bạn đang xem số liệu bán hàng có ba điểm giao nhau của dữ liệu thứ nguyên.
 Đối với những tình huống như vậy, thiết kế thứ nguyên và dữ kiện là một cách tiếp cận tốt hơn. Nói một cách đơn giản, bạn có thể tạo một bảng dữ kiện bán hàng trung tâm đơn giản có trường số lượng bán hàng và nó tạo kết nối với tất cả các bảng thứ nguyên bằng cách sử dụng mối quan hệ khóa ngoại.
Đối với những tình huống như vậy, thiết kế thứ nguyên và dữ kiện là một cách tiếp cận tốt hơn. Nói một cách đơn giản, bạn có thể tạo một bảng dữ kiện bán hàng trung tâm đơn giản có trường số lượng bán hàng và nó tạo kết nối với tất cả các bảng thứ nguyên bằng cách sử dụng mối quan hệ khóa ngoại.
Nhiều lần tôi đã xem qua bảng giá trị tên. Bảng tên và giá trị có nghĩa là nó có khóa và một số dữ liệu được liên kết với khóa. Ví dụ trong hình bên dưới, bạn có thể thấy chúng ta có một bảng đơn vị tiền tệ và một bảng quốc gia. Nếu bạn xem kỹ dữ liệu, chúng thực sự chỉ có một khóa và giá trị.
 Đối với các loại bảng như vậy, việc tạo bảng trung tâm và phân biệt dữ liệu bằng cách sử dụng trường loại có ý nghĩa hơn.
Đối với các loại bảng như vậy, việc tạo bảng trung tâm và phân biệt dữ liệu bằng cách sử dụng trường loại có ý nghĩa hơn.
Nhiều lần chúng ta bắt gặp dữ liệu có hệ thống phân cấp con mẹ không giới hạn. Ví dụ: hãy xem xét một kịch bản tiếp thị đa cấp trong đó một người bán hàng có thể có nhiều người bán hàng bên dưới họ. Đối với những trường hợp như vậy, việc sử dụng khóa chính tự tham chiếu và khóa ngoại sẽ giúp đạt được điều tương tự.
 Bài viết này không có ý nói rằng không tuân theo các hình thức thông thường, thay vào đó đừng làm theo chúng một cách mù quáng, hãy nhìn vào bản chất dự án của bạn và loại dữ liệu bạn đang xử lý trước.
Bài viết này không có ý nói rằng không tuân theo các hình thức thông thường, thay vào đó đừng làm theo chúng một cách mù quáng, hãy nhìn vào bản chất dự án của bạn và loại dữ liệu bạn đang xử lý trước.
Nguồn: Internet >>> Đọc thêm:
KHÓA HỌC DATA WAREHOUSE : TỔNG HỢP, CHUẨN HÓA VÀ XÂY DỰNG KHO DỮ LIỆU TRONG DOANH NGHIỆP
KHÓA HỌC DATA MODEL - THIẾT KẾ MÔ HÌNH DỮ LIỆU TRONG DOANH NGHIỆP
LỘ TRÌNH TRỞ THÀNH DATA ENGINEER CHO NGƯỜI MỚI BẮT ĐẦU
DATA ENGINEER LÀ GÌ? CÔNG VIỆC CHÍNH CỦA DE? CÁC KỸ NĂNG CẦN THIẾT
Link nội dung: https://truyenhay.edu.vn/thiet-ke-database-a66003.html